Introduction
I've spilled a lot of digital ink on this blog talking about the magic of compile-time workflows, using tools like Gatsby to build rich, dynamic web apps without needing a runtime Node server.
This works great for static content that changes infrequently (eg. blog posts), but how might we build something which relies on rapidly-changing user-generated data, like a hit counter?
In this tutorial, we'll cover how to use to drive a hit counter, like the one on my blog:
Link to this headingWhy would I want a hit counter?
So here's the thing: enough time has passed that the 90s are cool and retro now. It's “on-trend”—there's been a bunch of cool nostalgia-ware this year:
- Webrings are back! There's the Sidebar Webring and the Weird Wide Webring, among others.
- Vistaserv founders got 90s-style text rendering working in the browser.
- Internet sensation Jordan Scales built 98.css, a design system that faithfully recreates my third-favourite operating system of all time:
Hit counters are quintessential “early web”. Your Geocities site wasn't complete without one!
Even if you don't want to build a hit counter, I encourage you to keep reading; hit counters are a fun example, but the tools we'll learn about in this post open all kinds of doors for your static site.
Link to this headingTools
There are a few moving parts here that need to come together. Let's get a high-level picture of the terrain.
Link to this headingThe frontend
I'll be using Gatsby in this tutorial, but any React-based frontend will work (like Next.js or create-react-app).
For the UI, we'll use React Retro Hit Counter, a package I created a couple years back. It gives us a React component we can use to display the hit count. It's also very customizable, in case you wanted a more minimal / modern aesthetic.
The package exposes a presentational / visual component, but it doesn't handle any of the data-fetching and state management for us. There are more pieces to this puzzle.
Link to this headingThe backend
We're building a static site, so we don't have access to a runtime Node/Express server.
Platforms like Netlify and Vercel offer "Functions as a service". Instead of deploying a persistent application to a specific server, you deploy individual functions that fire up on request.
These platforms both use AWS Lambda under the hood, and they sand down some of the sharper edges. For example, when working with AWS Lambda directly, you need to do a fair amount of processing and bundling to ensure that each function is its own self-contained mini-application; both Netlify and Vercel take care of this for you, and they integrate it directly into the build-and-deploy process.
I've written about using Netlify Functions with Gatsby; check out that post for more context!
Link to this headingThe database
I've chosen FaunaDB, a modern NoSQL hosted database built for serverless environments.
The choice for database felt a little bit arbitrary; our needs are pretty minimal, we really just need a place to store and retrieve a collection of numbers! But I've been pretty impressed with FaunaDB. It comes with an awesome admin panel, and it's specifically built to be used with serverless functions. I imagine it scales super well.
Here's a quick example showing how the FaunaDB JS API works:
js
FaunaDB is a “database-as-a-service”; they host it, and you pay for what you use.
Link to this headingOur data model
Here's how Fauna databases are structured:
- A database is similar to an SQL database. I created one for my entire site, which holds multiple types of data.
- A collection is a set of individual items, like an SQL table.
- A document is a single piece of data, like an SQL row.
- An index lets us query a collection, to look up documents based on a specific field.
This is very similar to how MongoDB works, if you've used it before.
For our data model, we want to have 1 document per blog post, and it should track that post's slug, as well as the # of hits. Here's an example document:
json
Each of these posts will be stored in a collection, and will be indexed by slug.
Link to this headingGetting set up with Fauna
If you haven't already, sign up for an account with Fauna.
Create a new database, named after your site, and a new collection, named hits. You can leave every other field as its default value:
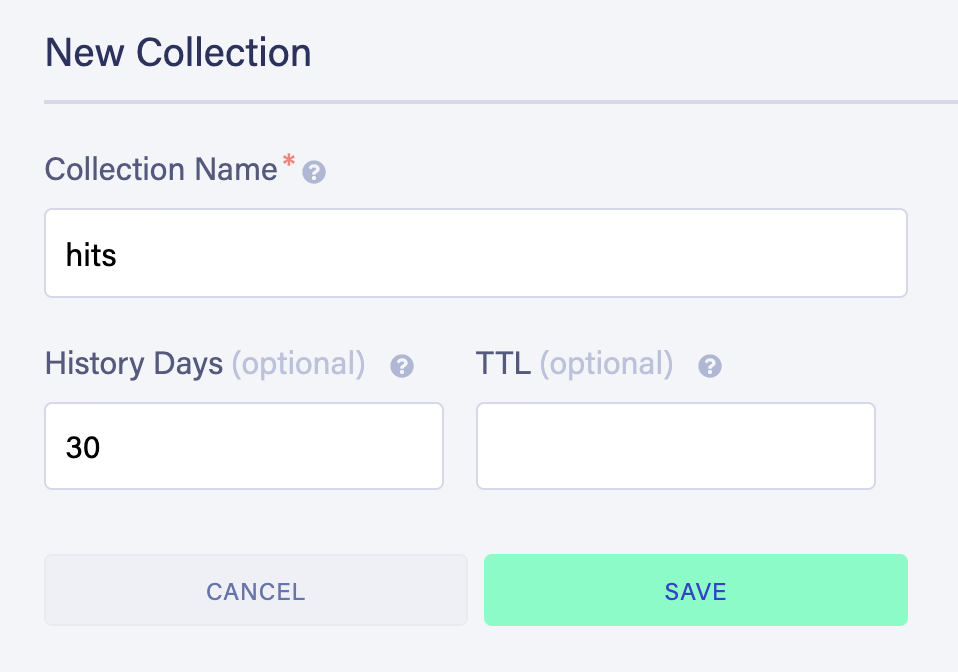
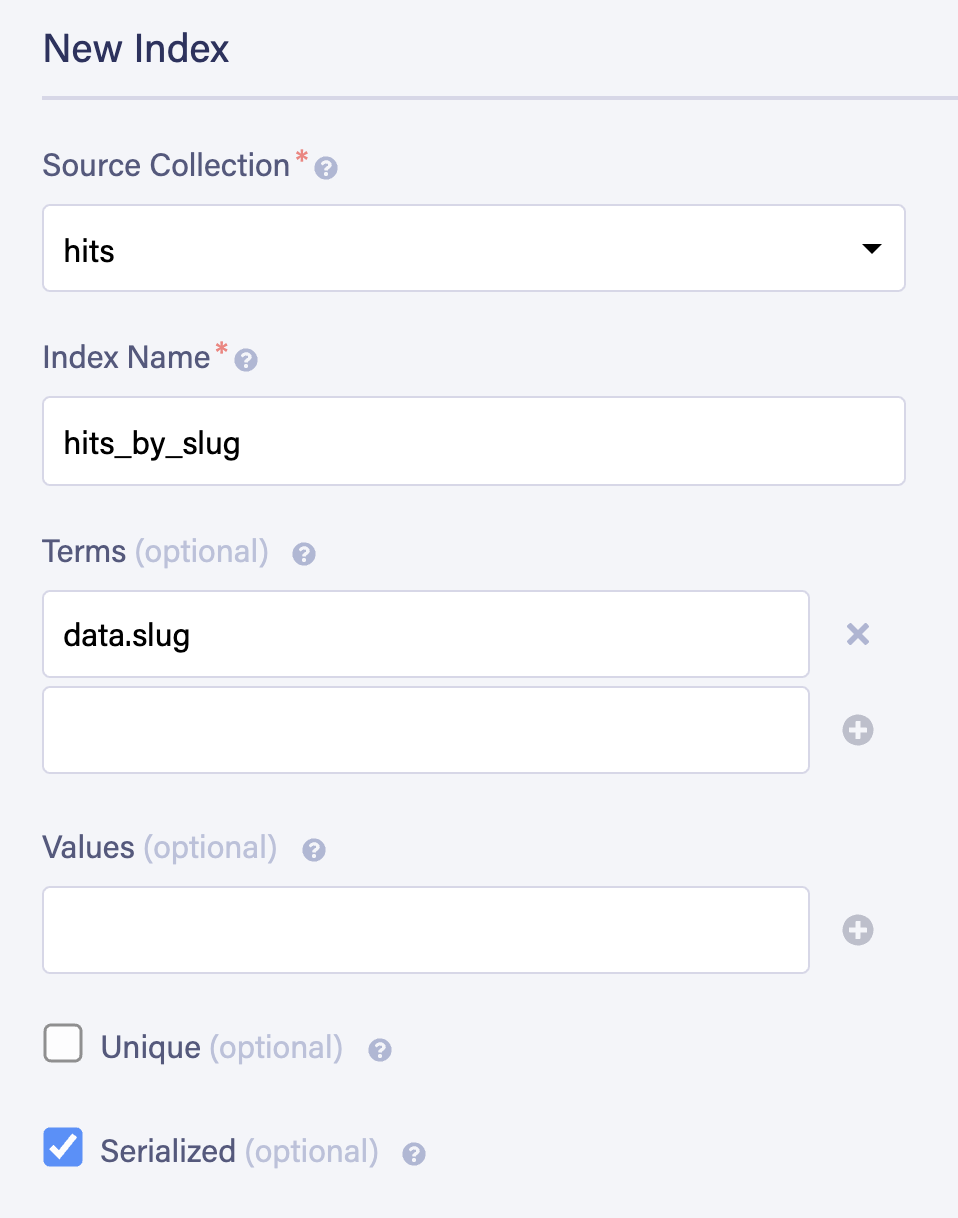
Let's also create a new index. Indexes are critical in FaunaDB; you don't query a collection, you query on index.
In this case, we'll source it from our hits collection, and name it hits_by_slug. We can specify which fields we will want to query by with "Terms": we'll set it to data.slug.
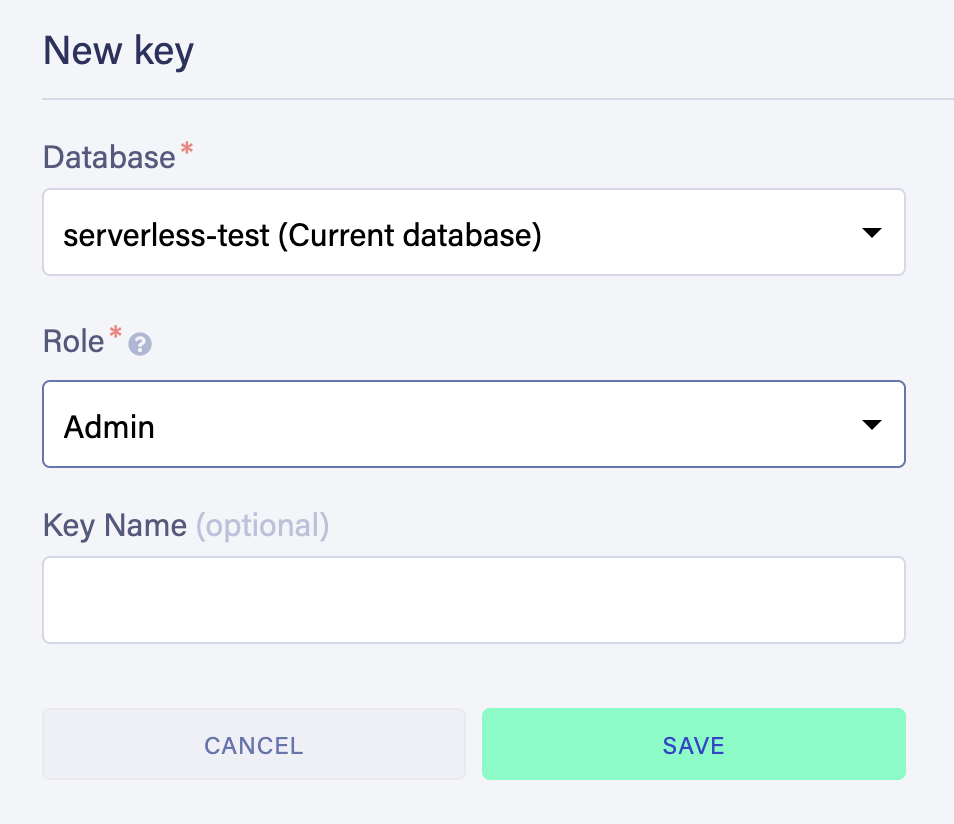
We'll need our FaunaDB secret key, to authorize the ability to access this database. Click “Security” in the left navigation, and then click “New Key” in the header. Click “save”:
We'll want to store our secret key in an environment variable called FAUNA_SECRET_KEY. Environment variables are beyond the scope of this tutorial, but here are some links if you're not sure how to do this:
Finally, we'll need to install the FaunaDB dependency:
bash
Link to this headingSetting up Functions
Before we can start writing our serverless function, we need to figure out where to put it! Netlify and Vercel each have their own standardized place:
- A top-level
functionsdirectory for Netlify - A
apidirectory insidepagesfor Vercel
The name of your functions file will be used in the route. Create a new file called register-hit.js. You'll be able to access it at the following URL:
- For Netlify,
/functions/register-hit.jswill be served at/.netlify/functions/register-hit - For Vercel,
/pages/api/register-hit.jswill be served at/api/register-hit
Both Netlify and Vercel offer development tools that let you test this locally. I cover this in my article about Netlify Functions. For Vercel, check out their "vercel dev" announcement post.
Link to this headingWriting our “register-hit” function
Let's write some pseudocode to figure out how our function should work:
pseudocode
Our function has 3 responsibilities:
- Create a document if it doesn't exist yet
- Increment the
hitsvalue - Return the
hitsvalue to be displayed on the page
It may bother you that 1 function is both setting and getting the value; we're violating the single responsibility principle! But I think it's justified. The alternative is to have two separate endpoints, which means twice as many function invocations, which costs twice as much money.
Here's what this looks like, in JS. The business logic is the same, but the wrappers vary by platform:
Link to this headingWiring it up on the frontend
When our page loads, we'll make a request to this function endpoint to increment the number, and retrieve it to display.
As outlined above, we're going to use a package for the actual UI. Install the dependency:
bash
Check out the package's documentation to learn more about it.
Create a new component called HitCounter, and add this code to it:
js
There's a lot going on here, so let's break it down.
Essentially, we're creating a smart HitCounter component that wraps around the presentational one we get from NPM. It's going to fetch the data from our serverless function, and pass it along to that component.
We keep track of the number of hits in React state. We initialize it to undefined. The very first time our component renders, we won't have the data yet, so we have an early-return of null. We only want to show the hit counter when we know how many hits the page has.
We use useEffect to request our data immediately after mount. It'll invoke the function we wrote earlier, and return the current number of hits, which we'll set into state. This causes a re-render, and since hits is no longer undefined, we render the RetroHitCounter.
Our component takes a single prop: slug. This is a unique identifier for the specific article or page. It becomes a query parameter in our fetch request. This is crucial if we want to track individual pieces of content. We use slug in the useEffect dependency array, but this is more of a formality; we don't expect the slug to actually change.
Link to this headingFinding our component a home
We have a shiny batteries-included HitCounter component—what now?
You'll need to find a place in your project to render it. In a Gatsby/Next context, you could put it in every page-component you care about. You could also put it in a layout component.
You'll need to find a way to pass the slug to your component. This is outside the scope of this tutorial, since it depends entirely on your project's structure. In a Gatsby app, you should be able to fetch this with GraphQL.
Link to this headingIn conclusion
This tutorial covers how to create a hit counter, a delightful bit of flair sure to bring a smile to millennials' faces.
The core idea is much broader, though. With FaunaDB and serverless functions, we can build all kinds of stuff! On this blog, I use a similar technique for the “like” button, and I built an admin panel that lets me view the likes/hits for all of my articles.
It's never been easier to get up and running with serverless functions, and you get so much "for free" by using them: you don't have to worry about servers, maintenance, scaling...
For frontend devs, serverless functions and FaunaDB can be gateway drugs into full-stack development. So many new doors open up!
I can't wait to see what you build with these new tools 😄
Last Updated
September 28th, 2020