One of my New Years resolutions this year was to blog more. I rebuilt the blog from the ground up. Here's a before/after:
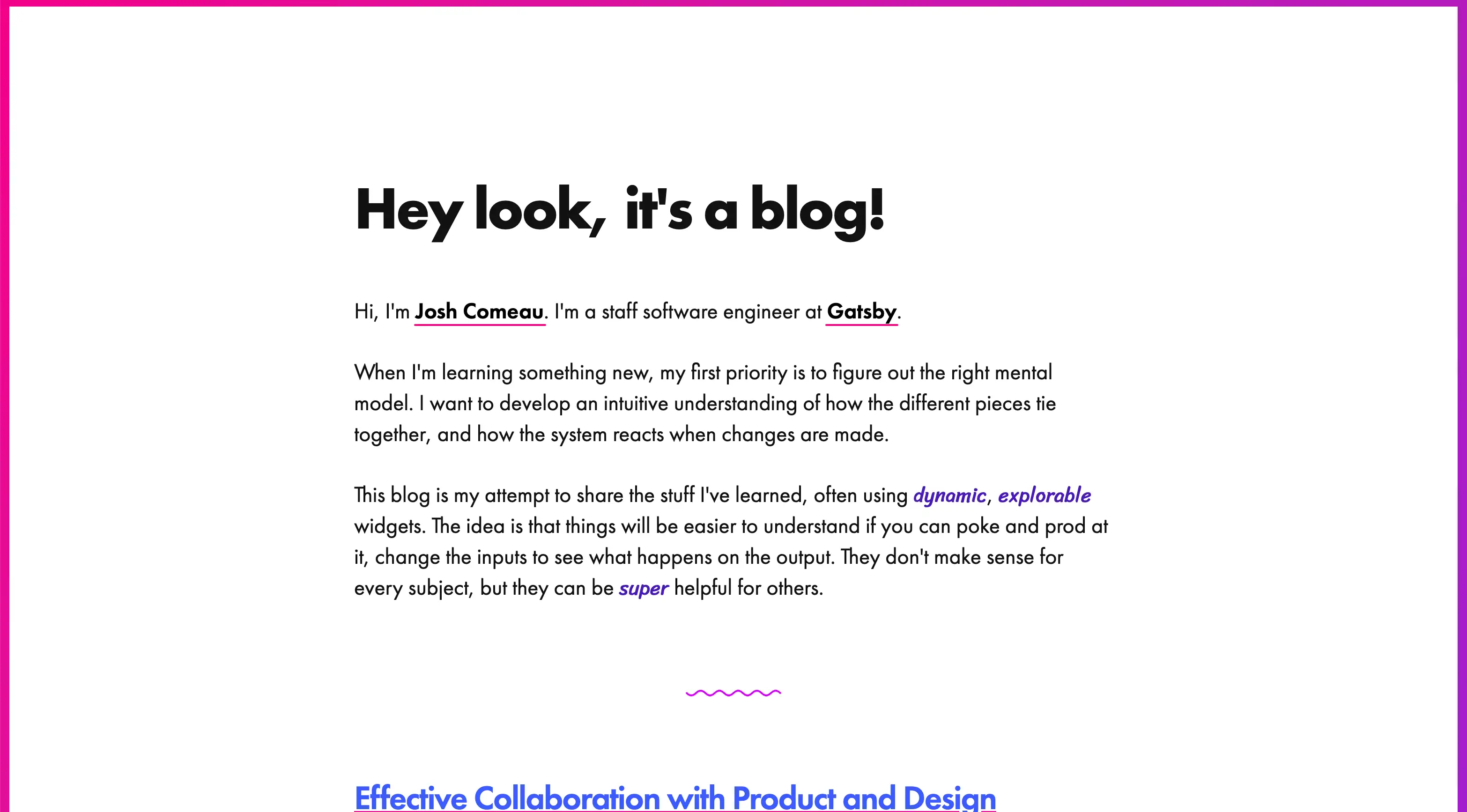
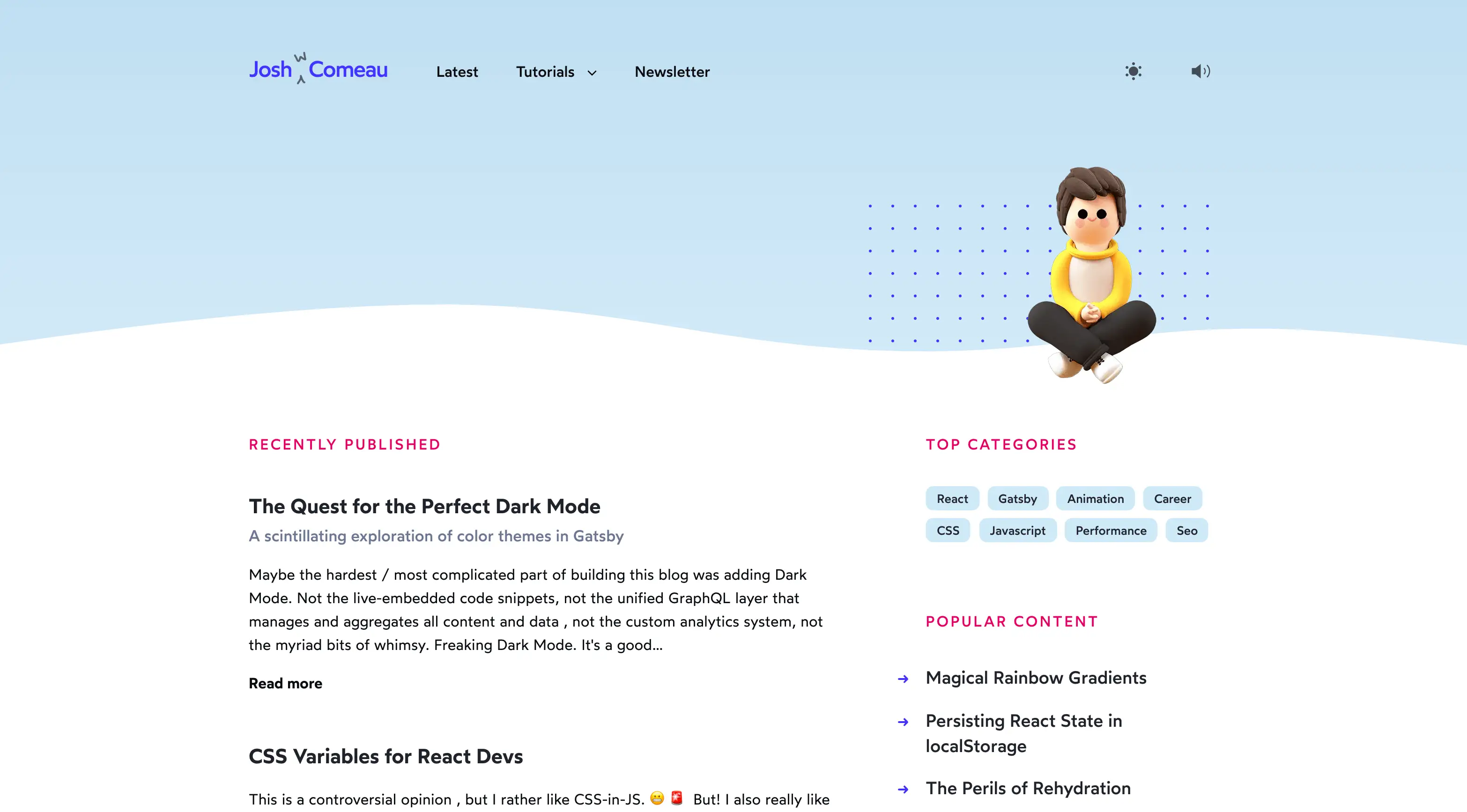
There were a lot of goals in this rebuild, but the main one was to give me a platform I could use in a more serious way. Even though it's still a personal blog, I wanted it to feel more like a community resource, something people come to trust as a good source of quality tutorials and articles.
A big part of this goal is to publish regularly! I've set a goal of at least 1 post a week. Since launch, I've managed to keep to this goal, and I'm hoping to keep the trend going.This current self-indulgent blog post in particular doesn't count towards that goal 😅 I launched “Incredimental Builds” earlier this week!
While most of the changes have been embraced by my readers, there's been one change that has surprised a few people: my new blog is not open-source. I've gotten a lot of questions about this, and thought it would be good to address this, and share some of my reasoning 🙂
Link to this headingLower friction
A big part of it is around friction. In order to keep my velocity of new posts high, I need publishing to be as effortless and friction-free as possible. Having an open-source blog would add friction in a few ways.
Link to this headingSource control
My blog uses MDX(opens in new tab), a fancy version of Markdown which lets me embed React components. The posts are checked into the Git repository rather than stored in a CMS.
Each post has an isPublished boolean in its frontmatter. At any given moment, I have between 1 and 5 draft posts. Sometimes a draft lasts for weeks before I get around to finishing and publishing it!
If this blog was open-source, all of those drafts would be public. I don't like this idea 😅 I want to control when a post is publicly available!
There are solutions for this; I could keep the posts in a separate repo, or use Git submodules*shudder*. It would complicate my process though. And the more complicated the process is, the less motivated I'll be to work on it.
Link to this headingCode standards
For an upcoming post, I built a little VennDiagram component:
This component is not particularly well-built; for one thing, it's not very flexible. It only takes 2 circles, and I can't control the ratio between them. I haven't tested it with long or short strings.
Since it's closed-source, none of that matters to me. But if it was open, folks would want to grab it to use in their own projects. I'd feel a certain responsibility to make sure that it works well, or at least to make sure that its shortcomings are well-documented. And I don't want that responsibility right now.
Link to this headingCopycats
A while ago, I offered to review developer portfolio websites for folks early in their career on social media. I got several hundred requests 😬
I discovered a trend: some developers were blatantly copying popular portfolios. For example, check out this beautiful portfolio(opens in new tab) by Brittany Chiang:

I got three developer submissions that were identical to this. I don't mean that they were heavily inspired, I mean that they forked the repo, swapped out the name and projects, and called it doneTo be accurate: one of the devs recreated it from scratch, but it looked absolutely identical..
The repo(opens in new tab) has an MIT license, so these portfolio copycats weren't violating any rules or laws or anything… But it makes me sad to see someone else try to take credit for the amazing work Brittany did (even if you add attribution on Github or in the site's footer or something, most folks will never see that).
The problem with dumping a whole project on Github is that it's so easy to fork it, change a few things, and ship it. I could use a restrictive license, but do I really want to try to track / enforce license violations?
It's ironic, because I actually really like the idea of people taking and using parts of this website; for example, I'm currently writing a post on , and I do hope people nab that idea for their own projects. But it's different when it's literally the whole site.
There's also the fact that a forked open-source repo is forever out of your control, which can be problematic. Blogger Tania Rascia(opens in new tab) has written:
I'm realizing that having my entire website including all my writing public and open source in a single repo you can fork was a bad idea, based on how many people fork the site and just leave all my posts and personal information in there.
People can still create copies of the pages on my blog, but forking makes it way easier / more likely (and those forks are public by default).
Link to this headingSecurity
When I relaunched my blog, it came with a nifty feature: the ability to “like” articles:
Like Medium claps, you can “like” an article multiple times, up to 16 times.
I added this feature because I thought it would be cute; it doesn't really do anything. Unlike on a platform like Medium, I'm the only author here, so there's no algorithm I'm trying to game in order to give my posts a leg up. I suppose it does help me learn which posts are valuable to you folks, though I suspect the signal-to-noise ratio is very low (if my post starts trending on link aggregators, for example, the like-ratio plummets).
Link to this headingHacked!
A couple days after the launch, I woke up to something rather startling:

The post had only received a few hundred visitors, so this number made no sense. I dug into the data, only to find that I had been hacked!
Remarkably, the culprit was prolific feature-uncoverer, rogue hacker(opens in new tab), and all-around badass Jane Manchun Wong!

This was a delightful surprise, but it was a little eye-opening; I'm using serverless functions for all backend code, and I pay per-invocation (both in terms of the functions and the database calls). Someone could cost me quite a bit of money if they decided to DDOS my endpoints!
I did some research and added some guards, but this is not my area; if I did open-source the codebase, it would make it easier for bad actors to find flaws in my safeguards.
It might surprise you to learn that this site and its newsletter costs about $130 USD a month to run; I don't make any money off the site, so this comes out-of-pocket. I'd really like to keep that cost as low as possible 😅
Link to this headingThe plan
For these reasons, I'm going to keep my blog closed-source for now.
I recognize that this is a bummer for folks who see something cool, and want to know how I've done it. But I do have a plan for this situation!
Rather than open-source a large and messy codebase, I'd prefer to write detailed tutorials for specific features. This has already begun—check out the following posts:
- The Quest for the Perfect Dark Mode(opens in new tab), for the site's light/dark mode logic
- Styling Ordered Lists with CSS Counters, for the ordered lists (like this one!)
- Magical Rainbow Gradients, for the newsletter "Subscribe" button.
I like this strategy because it's so explicit. With most of the code in this blog, a huge amount of the context only exists in my head; if you were to peruse the code, you'd have to fill in that context, and it could lead to problems. This way, I can guide you through how a thing works, what the tradeoffs are, what the limitations are. Context is included.
I have a huge list of things I want to write about. The VennDiagram component from earlier is on that list! We'll get there in due time 😄
If you're curious about the broad structure of the codebase, my old blog(opens in new tab) is still open-souce, and in terms of structure it hasn't changed dramatically. If you're curious how to set up an MDX developer blog, it could be worth a gander!
Finally: I have sourcemaps enabled for this site! Feel free to spelunk in the client-side source code through the browser. Just do be aware that all the previously-mentioned caveats about context still apply; it comes with no warranty, and I'm not responsible for any problems it causes in your codebase.
I know it's frustrating, but hopefully this helps y'all understand where I'm coming from. If you're curious about how something works, feel free to ask me on Bluesky(opens in new tab), or shoot me an email! It might give me a push to write a tutorial about it.
Last updated on
January 28th, 2025